|
本文(译文)发表在《数学译林》2009年第4期289-304页
如果第一次阅读本文,您可以先看: 1)引文统计局限性辨析 2)期刊影响因子辨析
这是《引文统计局限性辨析》最后的内容。无论是科学计量还是实际科研管理中,论文排序和科学家排序都是争议最大地方,所以作者一再强调,要搞清楚引文的内涵,要明智地使用统计数据,尤其不能忽略数据的问题;根据统计分析得出结论和解释需要符合实际情况。
3.论文排序 虽然影响因子及类似的引文统计数据在期刊排名中被滥用,但比这更基本的和更隐秘的滥用是:用影响因子来比较论文、人员、项目甚至是学科!这是一个日趋严重的问题。最近英国的科研评价又加剧了问题的严重性,不仅蔓延至许多国家,而且也危及到许多学科。
科学家很多时候会被要求用论文记录作为评价依据。在某种意义上,这并不是新鲜事物。人们常会听到诸如此类的说法:“她在权威期刊上发表了论文”或者“他的大部分论文都发表在低水平期刊上”。合理的评价应该是:某某科学家经常(或总是)发表论文的期刊质量只是评价其全部研究工作的诸多指标之一。然而,人们利用影响因子进行评价时总是将某一种期刊的好坏与该期刊刊载的每一篇论文的质量(抑或每一位作者)等同起来。这种趋势愈演愈烈。
汤姆森科技集团无疑在倡导这种做法:“也许在学术评价过程中‘影响’是最重要的,也是近来开始采纳的。影响因子可以提供个人发表论文所在期刊威望的粗略估计。”[THOMPSON:IMPACTFACTOR] 以下一些案例摘自世界各地数学家的报道,可以用来诠释人们在怎样实践上述建议。
案例1 我所在的大学最近引入了基于《科学引文索引》核心期刊的期刊分类方法。完全依据影响因子,将期刊分为3个等级。最高等级的期刊有30种,未包括1种数学期刊,第2等级的期刊有667种,其中数学期刊有21种。在最高等级的期刊上发表论文,学校将给予3倍的资助;在第2等级的期刊上发表论文将会获得两倍的资助。在核心期刊上发表论文将有15分的奖励。在汤姆森科技数据库收录的期刊上发表论文,则有10分的奖励。而科研人员的晋升需要获得一定的分值。
案例2 在英国,终身职位的大学教师每6年评定一次。连续的成功评价对于全部学术成就来说是一个关键。除个人履历外,评价中最关键的因素是对5篇已发表论文的排序。在最近几年,如果论文发表在汤姆森科技集团发布的前1/3期刊中,将会得到3分;如果在中间的1/3,得2分;在最后1/3,得1分(3个等级的列表依据影响因子计算得出)。
案例3 在我们系,都用公式在评价每个教员,即计算单个作者的论文当量,再乘以论文所在期刊的影响因子。决定晋级还是聘用,部分取决于这个公式。
除了上面的例子,我们还收到其它一些报告:人们正在有意或无意地使用影响因子来比较论文及其作者:如果期刊A比期刊B的影响因子高,那么在期刊A上发表的论文一定好于期刊B,作者A优于作者B。在一些案例中,这样的推理被拓展到院系的排名,甚至学科的排名中。
很久之前,人们已经知道,在一种期刊中,每篇论文的被引频次呈现高度偏斜分布,近似于幂律分布[Seglen 1996],[Garfield 1987]。这一点可以用一个例子来精确地加以证明。
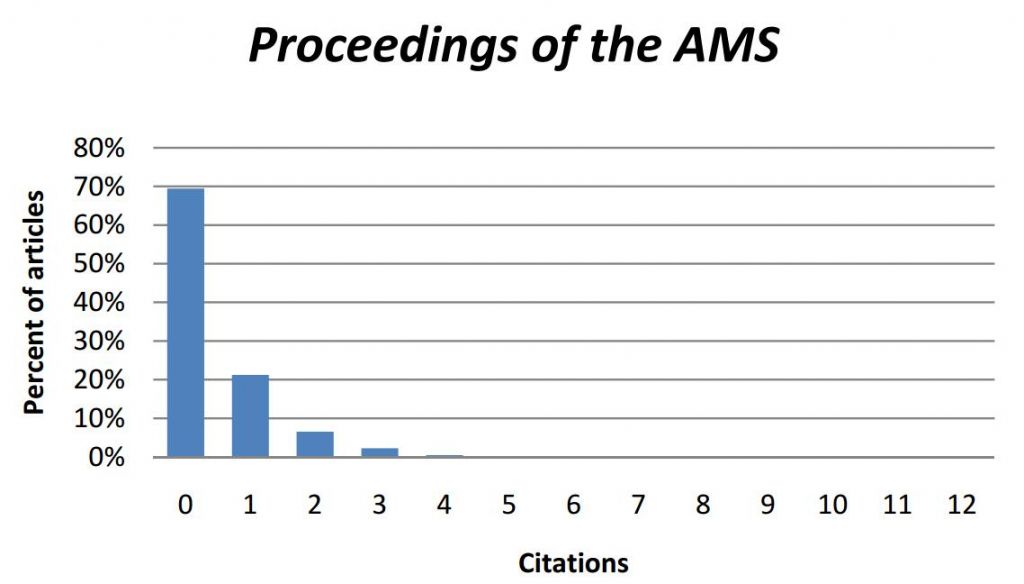
下图是《Proceedings of the American Mathematical Society(美国数学会公报)》2000-2004年论文的被引频次分布。该刊主要发表短文,通常篇幅不超过10页,2000—2004年间发表了2381篇文章f约15000页)。利用2005年(《数学评论》引文数据库收录的期刊进行统计,每篇文章的平均被引频次(即期刊的影响因子)为0.434。
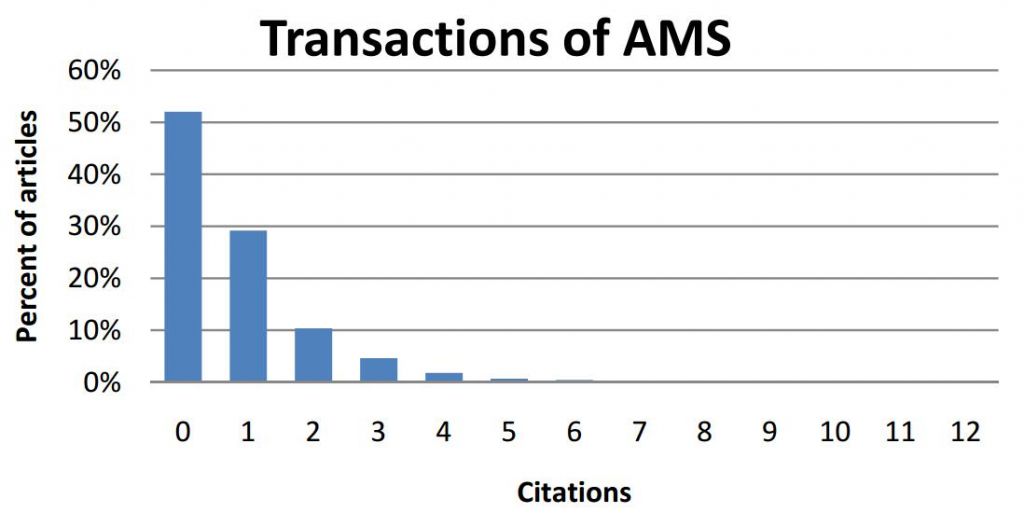
《The Transactions of the AMS(美国数学会会刊)》发表的文章篇幅较长,无论是从内容还是从范围看都更为充实。在与上图同样的时间内,《美国数学会会刊》发表了1165篇文章(超过25000页),引文频次为012。篇均被引频次为0.846,约为《美国数学会公报》的两倍。
现在假设有两位数学家,一位在《公报》上发表文章,另一位在《会刊》上发表文章。利用上面提到的评价规则,第2位的评价将会优于第1位,因为第2位数学家在影响因子较高的期刊上发表了文章。事实上两刊的差距有两倍之大吗?这是一个合理的评价吗?难道发表在《会刊》上的所有论文,其质量都好于《公报》达两倍之多吗?
当给出在《会刊》上发表的每篇论文都优于《公报》论文(在引文意义上)的评价时,我们无需质疑平均值,而是要提出一个概率问题:错误评价的概率有多大?随机选择的《公报》论文与随机选择的《会刊》论文至少有同样引文的概率有多大?
初步的统计表明:答案是62%。这意味着我们在62%的时间内是错误的,而随机选择的《公报》论文几乎和随机选择的《会刊》论文水平相当(甚至更好),尽管《公报》的影响因子仅为《会刊》的一半。所以,我们得出错误判断的几率要大于作出正确判断的几率。很多人对此都非常吃惊,但这是高度偏斜分布和影响因子时间窗太窄(也正因为此,零被引论文的比例很高)造成的结果(狭窄的统计时间窗(只用一年的期刊作为引文来源,引文统计的目标年为5)呈现的偏斜分布说明大多数论文没有或很少被引用。从直观上来看,显然随机抽取论文的统计结果常常是等同的。事实上,很多文章没有引文(或只有少量引文)是因为引文周期长,就数学论文而言需要花费很多年的时间来积累引文。如果我们对于来源期刊和引文统计年限都选择更长的时间,那么,引文量将会随之增长,用引文行为来区别期刊也会因此变得更加容易。Stringer[Stringer-et al.2008]在分析引文时用到这种方法。他们的方法表明:只要时间窗足够宽,每篇文章的引文分布将会呈现对数正态分布。这样就提供了一个机制可以通过比较引文的对数正态分布来比较两种期刊。无疑,这种方法比使用影响因子更加复杂。然而,它也只考虑了引文,并无顾及其它因素。——原注)。这就是精确统计思维的价值,而不是凭直觉得到的观察。
下面是另一个期刊统计的典型例子。对两种期刊的诸项选择并无特殊之处:例如都是在相同的时间窗内,《Journal of the AMS(美国数学会杂志)》的影响因子是2.63,相当于《公报》的6倍。然而随机抽取的《公报》论文有32%与《美国数学会杂志》具有相同的水平(在引文意义上)。
尽管说影响因子没有给出期刊中单篇论文的信息是不正确的,但是实际上影响因子给出信息的模糊性令人吃惊,并极易产生误导。
以上3个例子说明,用影响因子代替单篇论文实际被引频次的作法多少缺乏合理的基础。如果不正确的概率超过一半(或1/3),据此就可以断言,这种做法肯定不是评价的好方法。
一旦人们认识到用影响因子代替每篇论文实际被引频次的作法意义不大时,接着也会认识到用影响因子来评价论文的作者、项目和学科也是毫无意义的。影响因子及均值指标总体上过于粗糙,没有给出更多的信息,因而也就不能作出合理的比较。
当然,人员的排序与其论文的排序并不相同。但是如果你想只用引文来测度论文质量,并为某人的论文排序时,你应该从计算论文的引文入手,用论文所在期刊的影响因子评价并不合理。
4.科学家排序 基于引文统计的影响因子已广为人知,近来又有一些其它的统计指标为人们所倡导。下面3个用于个人排名的指标只是其中的一小部分。
h指数:科学家发表的n篇论文每篇至少被引n次,他(或她)的h指数为n值(原文为:“A scientist’s h-index is the largest n for which he/she has publishedn articles,each with at least n citation。”——校注)。
h指数是本报告中提到的、最流行的统计指标,它由J.E.Hirsch提出,主要是用引文分布的高端部分来测度研究人员的科研成果[Hirsch 2006]。目的是用一个数字代替论文数量和引文频次两个指标。
m指数:科学家的m指数是其h指数除以第1篇论文发表至今的年份。Hirsch在他上面提到的文章中提出这种计算方法。m指数是为弥补年青科学家没有来得及发表很多论文和获得引文的缺憾而设计。
g指数:当科学家的佗篇最高被引论文的被引频次大于等于佗的平方时,n值即为g指数。(原文为;“A scientist’s g-index is the largest n for which the n most cited papers have atotal of at least n2[n的平方] citations。"——校注)
g指数由Egghe在2006年提出[Egghe 2006],h指数没有考虑到n篇论文中处在顶端的论文具有超常引文的现象,而g指数可以弥补这一不足。
还有更多的指数,其中多数是从上述指数中衍生出来的系列指数。这些指数都在考虑论文的年龄和作者的数量([Batista-Campiteli-Kinouchi-Martinez 2005],[Batista Campiteli-Kinouchi 2006],[Sidiropouls-Katsaros-Manolopoulos 2006])。
在给出h指数定义的那篇文章中,Hirsch写道:提出h指数是因为其计算简便,而且可以对科学家日积月累的科研成就进行重要性、显示度和影响度的评价[Hirsch 2005,p.5]。他接着指出:当科研成就成为科研评价的重要标准时,在相同资源的竞争中,比较个人之间的差异,h指数是一个有用的尺度。
然而,上面的结论找不到任何令人信服的证据支持。为了证实h指数可以测度科学家终身研究成就显示度和重要性的论断,Hirsch分析了诺贝尔奖得主(以及一部分美国科学院院士)的h指数。他用实例指出这群人都有很高的h指数。因此可以推断:如果科学家获得了诺贝尔奖,那么他很可能拥有较高的h指数。但是如果不作进一步分析,假如有些人拥有很高的h指数,我们也无从知道他们获得诺贝尔奖或成为美国科学院院士的可能性有多大。这才是我们希望得到的信息,因为这种信息可以验证h指数的有效性。
在Hirsch的文章中,他提出h指数可用于比较两名科学家:“我认为两名h指数相近的科学家在科学影响力方面具有可比性,即使他们的论文总量和总被引频次完全不同。相反,如果两名科学家(从事科研工作的时间相同)论文和被引用次数都大致相等,而h指数却完全不同,那么h指数较高的科学家很可能更有造诣[Hirsch2005,P.1]。"
这些观点凭借常识似乎就可驳倒(假设有两名科学家,一位有10篇论文和每篇被引10次,另一位有90篇论文,每篇被引9次;或者一位有10篇论文和每篇被引10次,另一位有10篇论文,每篇被引100次,有人会认为他们研究水平相当吗?)(为了验证h指数的计算丢失了多少信息,这里给出了一个真实的案例:一名处于职业生涯中期的著名数学家,发表研究性论文的数量为84篇。其引文分布如文末左图。我们注意到有接近20%的论文获得了大于或等于15次的被引频次,这15篇论文实际得到的被引频次分布如文末右图。然而,在Hirsch的分析中,没有考虑到全部信息。人们仅仅记住了h指数等于15,也就是说被引最高的15篇文章,其被引频次大于等于15。—一原注)
Hirsch赞美h指数的长处,认为它优于任何评价研究人员科研成果的单一数字指标[Hirsch2005,p.1]。但是他既没有定义什么是“更优”,也没有解释为什么评价中要用单一数字指标。
虽然人们对h指数已经给出了一些评论,但缺乏严谨的分析。很多研究重在分析聚合效度,即h指数与基于论文、引文的计量指标高度相关,例如发表论文的数量和总被引频次。既然所有的变量都是相同的基本现象的函数,即论文的函数,所以这种相关性就不足为奇了。在一篇备受关注的、与h指数相关的文章中[Lehmann-Jackson-Lautrup2006],作者通过更深入的分析证明h指数(确切地说是m指数)并不比篇均引文指标更“好”。即使是在这篇文章中,作者也没有给出“好”的确切定义。用经典统计方法[Lehmann-Jackson-Lautrup 2006]也可以证明,h指数的可靠性不如其它测度指标。
h系列指数不仅被用来比较同一学科内的人员水平,甚至还用来比较不同学科间的人员水平([Batista-Campiteli Kinouchi 2006],[Molinari Molinari 2008])。也有人主张h指数可以用来比较机构和院系[Kinney 2007]。上面的想法都是过于轻信用一个简单的数字可以反映复杂的引用记录。实际上,与简单的引文频次柱状图相比,这些新指标的主要“优势”在于丢弃了引文数据的绝大部分细节信息,因此,才有可能对任意两位科学家进行排序。然而,即使是最简单的例子也能够用来说明被丢弃的信息正是我们了解科研过程所需要的。无疑,科研评价的目标不应该只是对任意两个人作出比较,而是要通过评价更好地了解科研工作。
在某些案例中,政府评价机构正在收集h指数或系列衍生指数作为评价数据的一部分,这是对数据的误用。遗憾的是,用一个数字对每位科学家排序是一个诱人的想法,这种想法的广泛传播常常会造成在较为简单的数据集中恰当使用统计推断的误解。
5.引文的内涵 那些推崇引文统计方法并将其作为科研质量评价主要工具的人并未回答一个本质问题:引文的内涵究竟是什么?他们收集了大量的引文数据,他们为统计而处理数据,然后他们宣称评价结果是“客观的”。然而,这里的评价结果来自对统计数据的解释,而这种解释又依赖于引文的内涵,因此,是相当主观的。
在倡导引文方法的文献中,很难发现对于引文内涵的清晰描述:“引文索引背后的概念从本质上看很简单。信息价值的认可取决于利用它的人,与测度共同体范围内的影响相比,测度工作质量是一种更好的方法。在科学共同体中最广泛的成员(任何利用或引用文献资料的人)决定了研究思想及其原创者在知识体系中的影响力。”[THOMPSON:HISTORY]
“虽然用定量方法来测度科学家个人的水平很困难,通常认为发表论文多要好于发表论文少,并且论文的被引频次(与学科的引文习惯有关)是论文质量评估的有用指标。”[Lehman—Jackson—Lautrup2006,p.1003]
“引文频次反映了期刊的价值,‘用’是期刊的立足之本。”[Garfield 1972,p.535],[Garfield 1987,p.7]
“引文是对从知识中受益的致谢。”[THOMPSON:FIFTYYEARS]与引文相关的词是“质量”、“价值”、“影响”、“知识受益”。“影响”一词成了用来解释引文含义的通用词。这个词首次出现在1955年EugeneGarfield提出创建《引文索引》的一篇短文中。他写道:“因此,对具有重大意义的论文而言,《引文索引》就有了定量的数值。它有可能帮助历史学家测度论文的影响,即论文的‘影响因子’。”[Garfield 1955,P.3]
显然,此处“影响因子”一词和别处一样试图说明,由于引证文献是建立在被引文献基础之上,因此引文体现了科研工作自身繁衍进步的机制。
在大量关于引文实际含义的文献中都提到,引文比其它令人信服的含糊陈词更复杂。例如,Martinand Irvine在1983年有关科研评价的文章中写道:“用引文测度科研质量的根本问题在于我们忽略了为什么作者要引用这篇成果而不是其它。这个问题在上面提到过…。简单的引文分析假定既有的参考文献给出了一种高度合理的模式:引文主要用于反映对前人重要的或高水平工作的科学鉴赏,所有潜在的施引者都有相同的机会引用某一篇论文。”[Martin-Irvine 1983,p.69]
Cozzens在1988年关于引文含义的文章中指出,发表科学论文时引文的作用分为两大类,一类是“奖励性”引文,另一类是“修饰性”引文。前者的含义通常与引文内容有关联:施引论文因受益于被引文献而致谢。而后者的含义则完全相反:对前人文章的参考只是为了解释部分结论,也许与被引作者的结论完全不同。这种“修饰性”的引用只是科学交流的一种方式,并无“知识受益”的含义。当然,在某些情况下,引文也同时具有上述两种含义。
Cozzens的观测说明大多数引文都是“修饰性”引文。这一点已为大多数当代数学家的实践所证明(例如,在数学评论》引文数据库约300多万条引文中,有接近30%的引文是图书以及期刊的非研究性论文)。强调这一点为什么很重要呢?因为与倾向于引用经典论文的“奖励性”引文不同,“修饰性”引用的原因有很多:被引作者的声望(“光环”效应)、引用者与被引者之间的关系、期刊的可获得性(开放获取期刊是否更易被引用?),从一篇文章中引用多个结论的便捷性等等。上述因素几乎都与被引论文的“质量”无关。
即使是“奖励性”引用,动机也有多种,其中包括“流行度、负面引用、研究信息、说服、正面引用、提醒、社会共识’等[Brooks 1996]。通常,一篇论文的引文动机会包括上面提到的若干种。对于部分重要成果来说,有时会产生“消失”效应,即这类成果发表后立即成为其他工作的组成部分,并成为进一步引用的基础。此外,还有一些引文与其说是对杰出研究的“奖励”,不如说是对有瑕疵的结论或思想的批评。这份报告提供了很多此类“批评性”引文的案例。
引文的社会性是一个复杂问题,它超越了本报告的讨论范围。然而即使是初步的讨论,也能表明引文的含义并非那样简单,基于统计的引文数据也并非像其倡导者宣称的那样“客观”。
有人争辩说引文的含义无关紧要,因为基于统计的引文数据与其它的科研质量评价(如同行评议)方法具有很高的相关性。例如:英国大学联盟早先发布的(证据报告》认为:由于相关性的原因,引文统计数据能够(也应该)取代其它的评价指标:“《证据报告》认为文献计量学方法能够创建一套符合科研人员感知的质量评价指标。”[Evidence Report 2007,P.9]
由此似乎可以得出以下结论:不管基于统计的引文精确含义如何,都应该替代其它评价方法,原因是由引文得到的结论往往与其它方法相似。这种论证不仅陷入了一种循环,而且,这种推理上的错误也是显而易见的。
6.明智地使用统计数据 对科研评价的客观定量数据(统计数据)过于信赖,既不新鲜也不是孤立现象。《害人的谎言与统计数据》是2001年社会学家Joel Best撰写的一本畅销书,书中雄辩地写道:“在传统文化中,人们认为某些事物具有神奇的力量,人类学家称之为神器。在人类社会中,统计数据就是一种神器。好象它们不仅仅只是数字,而是具有一种魔力;人们把它们视为真理的强有力的表达形式;认为统计数据可以从混沌和复杂的现实中提取简单的事实;利用统计数据可以将复杂的社会问题转化为更易于理解的估计数值、百分数、比率。统计数据在引导我们所关注的问题;统计数据向我们展示,应该关心什么,应该在多大程度上关心之。从某种意义上说,社会问题可以变身为统计数据,因为我们确信统计数据是真实和确凿的。统计数据达到了一种神器的境界,用不可思议的力量左右着人们对社会问题的理解。人们还认为统计数据发现的是真相,而不是制造的数字。”[Best 2001,p.160]
无论是在国家层面还是机构层面的评价上,人们对魔法般的引文统计数据有一种迷信。这种迷信在描述科研评价实践的文献中比比皆是,在推崇h指数及其系列衍生指数的论文中也可以见到。
在近期的研究中,这种看法更加凸显:为分析引文,有人试图用更为复杂的数学算法来改进影响因子,其中包括pagerank算法([Bergstrom 2007],[Stringer-Sales-Pardo-Nunes 2008])。这些支持者所提出的算法功效未被分析所证实,也难以评价。由于这些算法的基础是更复杂的计算方法,其背后的假设不易为多数人洞悉。(Bergstromf[Bergstrom 2007]使用了pagerank算法赋予每一次引文以权重,然后用引文加权平均值计算“影响因子”。pagerank算法的优点在于它考虑了引文的"价值"。但从另一个角度讲,该算法的复杂性也会带来风险,因为最终的结果很难理解。例如,所有的“自引”都被忽略,也就是说,发表在期刊J上的论文,在其全部的引文中,5年前的引文都未计算在内。这并不是“自引”一词的正常含义。对《数学评论》引文数据库的部分数据进行粗略的统计表明,大约扔掉了1/3的引文。Stringerf [Stringer et al.2008]提出的算法很有意义,部分是因为它试图去处理不同的引文时间尺度,并解决在此期刊和在彼期刊中随机抽取论文进行比较的问题。这种算法的复杂性很难让大多数人对其结论作出评价。在该文第2页提到一个值得关注的假设:“我们首先假定期刊J上发表的论文符合‘质量’指标的正态分布…”这似乎与平常的经验相悖。——原注)正因为我们将排名和数字视为真理而不是作品,所以才会对它们肃然起敬。
科研工作并不是第一种经审查后方可获得政府资助的活动。在过去的10年中,从教育系统(学校)到卫生保健系统(医院,甚至个体外科医生),人们试图对一切事物进行定量评价。在其中一些事例中,统计学专家介入进来,提出了如何获得合理的数据以及如何正确使用统计数据的建议。如果说在医学实践中需要咨询医生的话,那么在统计实践中也一定需要咨询统计专家(或者听取建议)。[Bird2005]和[Goldstein-Spiegelhalter 1996]是很好的两个例子。他们从事绩效评价而不是研究工作。前者是对公共管理部门的绩效进行监测,后者是对卫生保健/教育系统进行评价。他们提供了科研评价中如何明智使用统计数据的真知灼见。
特别是Goldstein和Spiegelhalter的文章给出了基于简单数字(例如学生的成绩和医学成果)的名次表(排序)。这种名次表与引文统计数据给出的期刊、论文和作者的排序特别有关。在这篇文章中,Goldstein和Spiegelhalter还概述了可用于任何绩效评价的由3个部分组成的框架。
7.数据 “再精致的统计方法也难以克服统计工作中的基础缺陷:数据收集的完整性和恰当性。”[Goldstein-Spiegelhalter 1996,p.389]这是对基于引文的绩效评价的重要观察。例如,影响因子是基于数据子集的统计,只包括了被汤姆森科技集团收录的那些期刊(我们注意到影响因子本身也是选刊的主要标准)。一些人对数据的完整性提出了质疑[Rossner-VanEpps-Hill 2007]。还有人指出可能还有更完整的其它数据集[Meho-Yang2oo7]。有几个研究团队将此付之实践,用Google Scholar计算引文统计数据,例如h指数。但是Google Scholar包含的数据经常是不准确的(例如自动从网页中抽取看起来像是人名的词汇),因此,要想获得科学家个人的引文统计数据很难,因为作者的唯一性很难被确定。在某些情况下和在某些国家中,收集准确的引文数据也会遇到一些特殊困难。但是人们往往忽略了引文分析所需用的特殊数据的收集。如果统计数据有瑕疵,那么由此得到的结论很可能就是错误的。
8.统计分析及结论解释 “我们要特别注意以下一些问题:要对正确的统计模型作出说明、在对全部结果进行表述中不确定性至关重要、对于复杂因素得到的结果要进行方法上的调整、对于直观排名要考虑对它的依赖程度。”[Goldstein-Spiegelhalter 1996,p.390]
正如我们在前面写道的,引文统计数据在多数情况下被用于对论文、人员和项目的排序,但事先并没有给出具体的模型,而是用数据本身来充当模型。这种模型通常是模糊不清的。用循环的过程似乎给出了评价对象较高的位次,这是因为他们在数据库中本身排名就较高。另外,很少有人注意到各种排名的不确定性,也不去分析这种不确定性是如何影响排名的(例如影响因子的年度变化)。最后,那些影响排名的复杂因素(例如:特定的学科、期刊刊载论文的文献类型,某科学家是从事理论研究还是实验研究)在这类排序中通常会被忽略,尤其是在国家级的绩效评价中。
9.解释及影响 “考虑到广大公众的利益,本文对评价结果的比较进行了讨论。显然,在这个问题上需要慎重对待那些既关键又容易被忽视的局限性。在用任何一种方法对机构‘质量’进行有充分根据的测度中,对结果的调整是问题的一个方面,而分析者还应该认识到这样做的潜在影响:机构和科研人员为了提高其今后的‘排名’,可能会改变他们的行为。”[Goldstein-Spiegelhalter 1996,p.390]
科研评价也涉及到广大公众的利益。对于科学家个人来说,评价对一个人的职业生涯有着长期和深远的影响;对于院系,它能够改变未来成功的前景;对于学科,评估报告可以形成兴与衰的区别;对于如此重要的任务,人们必须了解评价工具的有效性和局限性。那么,引文究竟在多大程度上可以测度研究的质量呢?引文频次似乎与质量有关,凭直觉理解,高质量的论文会获得高水平的被引。但是正像上面解释过的,有些文章,尤其在某些学科,文章的高被引另有原因,与质量无关。这类文章并不遵循高被引论文一定是高质量的原则。所以,对引文统计排序的准确解释也需要加以更好地理解。另外,如果引文统计在研究评价中起主导作用,显然,作者、编辑甚至出版者都会为了自身的利益而设法去适应这种评价体系。当然,这样做的长期效应还不清楚,也没有加以研究[Macdonald-Kam 2007]。
科研成果评价辨析 | 
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜